基于MySQL,涵盖索引概念、B+Tree 结构、常见索引类型、SQL 示例与索引使用原则。
一、SQL查询执行过程
Section titled “一、SQL查询执行过程”select * from t where id = 1;
1.1 连接器
Section titled “1.1 连接器”负责维持/管理客户端的连接,权限的校验。修改权限不影响已建立的连接。 连接空闲后关闭由
wait_timeout决定,可使用show variables like 'wait%';查看,单位:秒。Command:
Sleep空闲连接;Query正在执行查询。
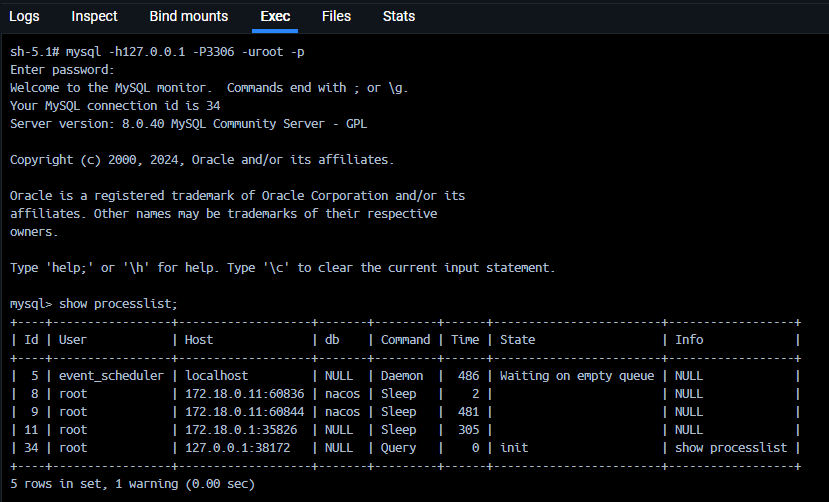
1.1.1 长连接
Section titled “1.1.1 长连接”- 解决长连接导致的内存占用问题
- 定期断开连接
- 如果MySQL版本 ≥ 5.7 则使用
mysql_reset_connection方法,重置连接,但是并不会关闭连接。 - 使用数据库连接池是较为常见的方式,如Java中常见使用
HikariCP/Druid配置maxLifetime保证定期断开连接;Go中只使用过database/sql的SetConnMaxLifetime/SetMaxIdleConns。
graph TD
Start((应用启动)) --> Init[建立持久连接]
Init --> Auth[身份认证/握手]
subgraph Loop [复用阶段]
Auth --> Wait{是否有新任务?}
Wait -- 是 --> Exec[直接执行 SQL]
Exec --> Wait
Wait -- 否 (空闲) --> Keep[维持心跳/Keep-Alive]
Keep --> Wait
end
Wait -- 应用关闭 --> Close[释放连接]
Close --> End((结束))
style Init fill:#dfd,stroke:#333
style Exec fill:#bbf,stroke:#333,stroke-width:2px
style Loop fill:#f5f5f5,stroke:#999,stroke-dasharray: 5 5
1.1.2 短链接
Section titled “1.1.2 短链接”graph TD
Start((开始查询)) --> Connect[建立 TCP 连接]
Connect --> Auth[身份认证/握手]
Auth --> Exec[执行 SQL 语句]
Exec --> Close[关闭连接/释放资源]
Close --> End((结束))
style Start fill:#f9f,stroke:#333
style End fill:#f9f,stroke:#333
style Exec fill:#bbf,stroke:#333,stroke-width:2px
1.2 分析器
Section titled “1.2 分析器”- 词法分析:select * from t where id = 1;
- 语法分析:根据词法提取的关键字判断是否满足语法,通常出现错误“You have an error in your SQL syntax”。
1.3 优化器
Section titled “1.3 优化器”- 索引选择
- join连接顺序
1.4 执行器
Section titled “1.4 执行器”- 权限校验:执行
select * from t where id = 1会先判断连接是否有表t的查询权限 - 执行过程
- 调用InnoDB引擎接口取表的第一行,判断
id的值是不是1;如果不是则跳过,如果是则将该行存储到结果集中 - 调用引擎接口获取下一行,重复相同的判断逻辑,直到该表的最后一行记录
- 执行器将上面遍历过程中满足条件的行组成的记录集作为结果集返回。
- 调用InnoDB引擎接口取表的第一行,判断
磁盘中存储的基本单位就是
页,一条数据就是一个页里面的一条记录,页相当于一个记录的容器。数据行放在User Records中。数据页就有点像JVM把Java类编译成class文件后的内容,class文件也包含元数据 + 常量池 + 字段/方法描述 + 字节码指令等。
- 为了避免一条一条读取磁盘数据,InnoDB采取页的方式,作为磁盘和内存之间交互的基本单位

2.1 文件头
Section titled “2.1 文件头”- 作用: 记录页的通用信息
- 页号: 标识当前页
- 上一页/下一页指针: 核心部分,所有数据页通过这两个指针组成双向链表
- 校验和 (Checksum): 用于和文件尾部对比,检查数据传输是否完整
- 重点: 理解双向链表结构。这是 B+ 树叶子节点能够进行范围查询(Range Scan)的基础。
2.2 页头
Section titled “2.2 页头”- 作用: 记录数据页特有的状态。
- 记录页内包含多少条记录
- 第一个槽(Slot)的位置
- 堆(Heap)中记录的数目
2.3 Infimum + Supremum Records (最小与最大虚记录)
Section titled “2.3 Infimum + Supremum Records (最小与最大虚记录)”- **作用:**两个特殊的“哨兵”记录。
- Infimum: 比页内任何用户记录都小的虚记录,最小虚记录,值为
-inf - Supremum: 比页内任何用户记录都大的虚记录,最大虚记录,值为
+inf
- Infimum: 比页内任何用户记录都小的虚记录,最小虚记录,值为
- 重点: 它们是记录链表的头和尾。所有用户记录都串在 Infimum 和 Supremum 之间。
2.4 User Records (用户记录)
Section titled “2.4 User Records (用户记录)”- 作用: 存储实际的用户数据。
- 结构: 记录之间通过单向链表连接
- 重点: 单向链表与逻辑顺序。记录在磁盘上的物理位置可能是不连续的,但通过头信息中的指针,它们在逻辑上是按主键大小有序排列的。
2.5 Free Space (空闲空间)
Section titled “2.5 Free Space (空闲空间)”- 作用: 页中尚未使用的存储区域。每插入一条新记录,就从这里申请空间划入 User Records。
2.6 Page Directory (页目录)
Section titled “2.6 Page Directory (页目录)”- 作用: 解决单向链表遍历慢的问题。
- 它将有序的记录分成若干组(也叫“槽” Slot)
- 每个槽存放组内最大的那条记录在页面中的地址。
- 重点: 二分查找 (Binary Search)。当我们在页内找数据时,不是从头遍历链表,而是先在 Page Directory 中二分定位到某个槽,再进入槽内进行小范围遍历。这是 InnoDB 页内查询极快的秘密。
2.7 File Trailer (文件尾)
Section titled “2.7 File Trailer (文件尾)”- 作用: 校验完整性。
- 包含 8 字节,存储校验和(Checksum)
- 重点: 防止“页断裂”。MySQL 默认页 16KB,而操作系统的页通常是 4KB。如果断电导致只写了 4KB,File Trailer 的校验值就会和 File Header 对不上,从而发现页损坏。
发现损坏后如何恢复?那就先理解写,InnoDB 将缓冲池中的脏页刷新到磁盘时,它不会直接写入数据文件。
- 将脏页先顺序写入内存中的双写缓冲区
- 分两次(每次 1MB)将双写缓冲区的内容写入磁盘上共享表空间中连续的物理位置(即磁盘上的 Doublewrite Buffer)。
- 在确认双写缓冲区的数据落盘后,再将页写入其真正的离散数据文件位置。
发现某个页的 Checksum 不匹配,确认原始副本,InnoDB 会去磁盘上的 Doublewrite Buffer 中查找该页的一个完好副本。
InnoDB 会去磁盘上的 Doublewrite Buffer 中查找该页的一个完好副本。
由于双写缓冲区在磁盘上是连续存储的,写入速度极快且通常能保证原子性,因此它提供了一个可靠的备份。
在页恢复到完整状态(虽然可能是旧版本)之后,InnoDB 再调用 Redo Log(重做日志)来应用宕机前未完成的事务修改。
以双写缓冲区为准进行物理还原,以 Redo Log 为准进行逻辑追赶。
如果关闭了 Doublewrite Buffer 数据库无法自动修复该页,通常需要依靠 最近的全文备份(Full Backup) 加上 Binlog 进行人工恢复